Redis + MySQL 缓存一致性:旁路缓存、删除策略与异常时序
最后更新时间:
Redis + MySQL 缓存一致性:旁路缓存、删除策略与异常时序
在后端系统里,Redis + MySQL 是非常典型的组合:MySQL 负责持久化,Redis 负责提升读取性能。但只要一个数据同时存在于数据库和缓存里,就一定会遇到一个问题:更新数据时,如何避免 Redis 和 MySQL 不一致?
这篇文章主要从实际开发角度讲清楚三个问题:
- 旁路缓存 Cache-Aside 是怎么工作的;
- 为什么更新数据时通常选择“先更新 MySQL,再删除 Redis”;
- 删除失败、并发读写、延迟双删这些异常时序应该怎么处理。
核心原则:MySQL 是数据源头,Redis 是派生缓存。缓存可以短暂不一致,但不能长期保存旧数据。
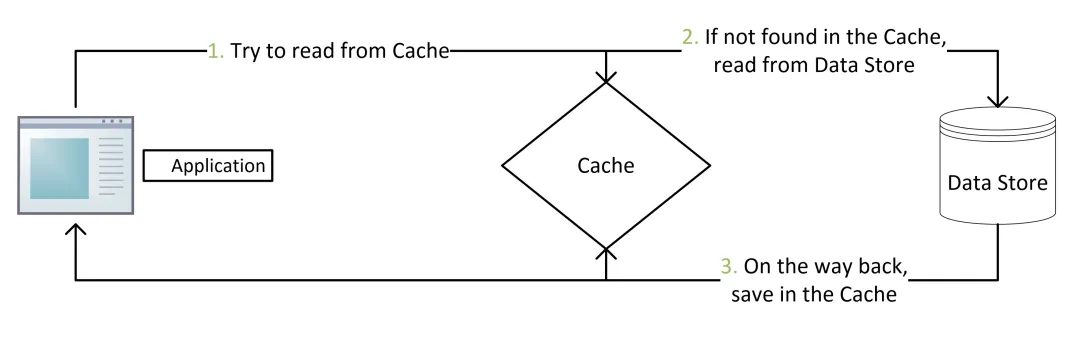
一、旁路缓存 Cache-Aside
最常见的缓存模型是 Cache-Aside Pattern,也叫旁路缓存。它的核心思想是:应用服务自己管理缓存,读数据时先查 Redis,缓存没有再查 MySQL,然后把结果写回 Redis。
Go实现的伪代码 :
1 | |
这里有两个细节:
- Redis 查询失败时,一般不要直接让业务失败,因为 Redis 是缓存,不是主存储;
- 写缓存时要设置 TTL,避免旧缓存永久存在。
二、更新数据时,为什么不是更新缓存?
很多人第一反应是:既然 MySQL 更新了,那我直接把 Redis 也更新成新值不就好了?
实际项目里更推荐:
1 | |
而不是:
1 | |
原因主要有三个。
第一,缓存可能不是单表数据。比如商品详情页缓存,可能包含商品表、图片表、SKU 表、评论统计等多个来源。数据库更新后,很难准确知道应该同步更新哪些缓存 key。
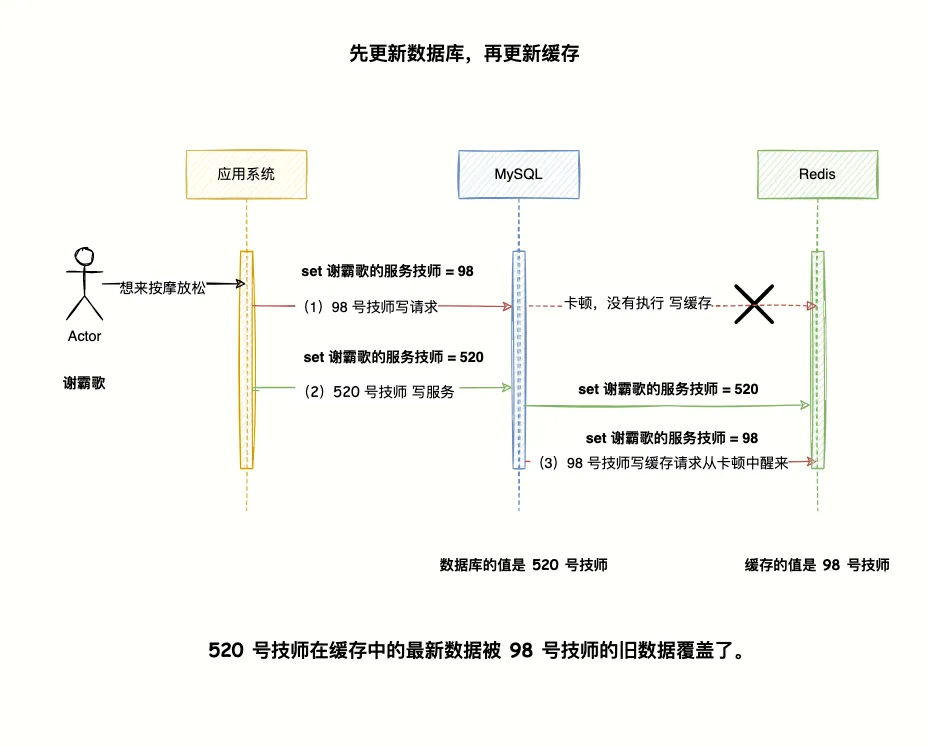
第二,并发写时容易出现旧值覆盖新值。比如两个请求同时更新同一个用户,A 先更新数据库,B 后更新数据库,但 A 最后才写 Redis,就可能把旧数据写回缓存。
第三,删除缓存更简单。缓存被删除后,下一次读取会重新查询 MySQL,并把最新数据加载到 Redis。
这里借用一个大佬的图来说明
三、为什么不能先删 Redis,再更新 MySQL?
如果写成下面这个顺序:
1 | |
在高并发下会有问题。
| 存储 | 数据状态 |
|---|---|
| MySQL | 新数据 |
| Redis | 旧数据 |
问题出在:写请求删除缓存后,还没来得及更新数据库;读请求进来发现缓存不存在,就查到了数据库里的旧值,并把旧值重新写回 Redis。
所以,一般不推荐“先删缓存,再更新数据库”。
四、先更新 MySQL,再删除 Redis 就绝对安全吗?
也不是。它只是更合理、风险更低。
极端情况下,仍然可能出现下面的时序:
1 | |
这种情况的发生概率较低,但不是不存在。它说明缓存一致性不是只看代码顺序,还要看并发时序。
解决这类问题,常见做法是 延迟双删。
五、延迟双删
延迟双删的思路是:更新数据库后先删一次缓存,过一小段时间再删一次缓存。第二次删除的作用,是清理并发读请求可能重新写入的旧缓存。
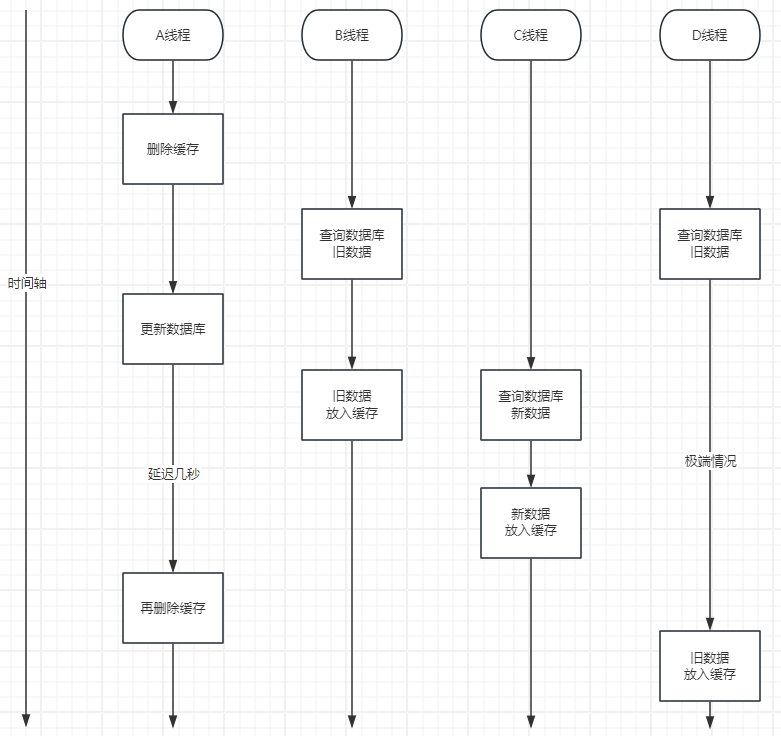
延迟时间不是固定答案,要根据业务接口耗时来定。一般需要覆盖一次读请求“查数据库 + 写缓存”的时间窗口。
六、删除 Redis 失败怎么办?
真正上线后,不能假设 Redis 删除一定成功。可能会遇到网络抖动、Redis 超时、连接池耗尽等问题。
如果 MySQL 已经更新成功,但 Redis 删除失败,就会出现旧缓存继续存在的问题。
所以在Redis缓存删除的时候需要加上判断条件来确保一致性
如果项目规模不大,可以用 MySQL 本地任务表兜底:
1 | |
应用更新数据时,把业务更新和删除任务写入同一个 MySQL 事务:
1 | |
后台任务定期扫描 PENDING 状态任务,执行 Redis 删除,失败就增加重试次数。
七、进阶方案:订阅 MySQL Binlog 做缓存失效
如果系统里有多个服务都会修改同一张表,单靠每个服务手动删除缓存很容易漏。这时可以考虑 CDC,也就是 Change Data Capture。
常见链路是:
1 | |
这种方式的优点是缓存失效逻辑集中,不依赖某一个业务服务是否记得删除缓存。缺点是架构复杂度更高,需要处理消息延迟、重复消费和失败重试。
所以小项目可以先用“更新 MySQL + 删除 Redis + TTL + 删除失败重试”;中大型系统再考虑 Binlog / CDC 方案。
八、TTL 兜底
不管采用哪种方案,缓存都应该设置 TTL。
Redis 的 EXPIRE 可以给 key 设置过期时间,过期后 key 会自动删除;TTL 可以查看 key 剩余生存时间。
1 | |
在代码里:
1 | |
为了避免大量 key 同时过期,可以给 TTL 加一点随机抖动:
1 | |
TTL 不能保证强一致,但能保证即使删除缓存失败,旧数据也不会永久存在。